Example videos generated on CelebV-HQ
Example videos generated on CelebV-HQ
Example videos generated on CelebV-HQ
Example videos generated on VoxCeleb2
Example videos generated on VoxCeleb2
Example videos generated on VoxCeleb2

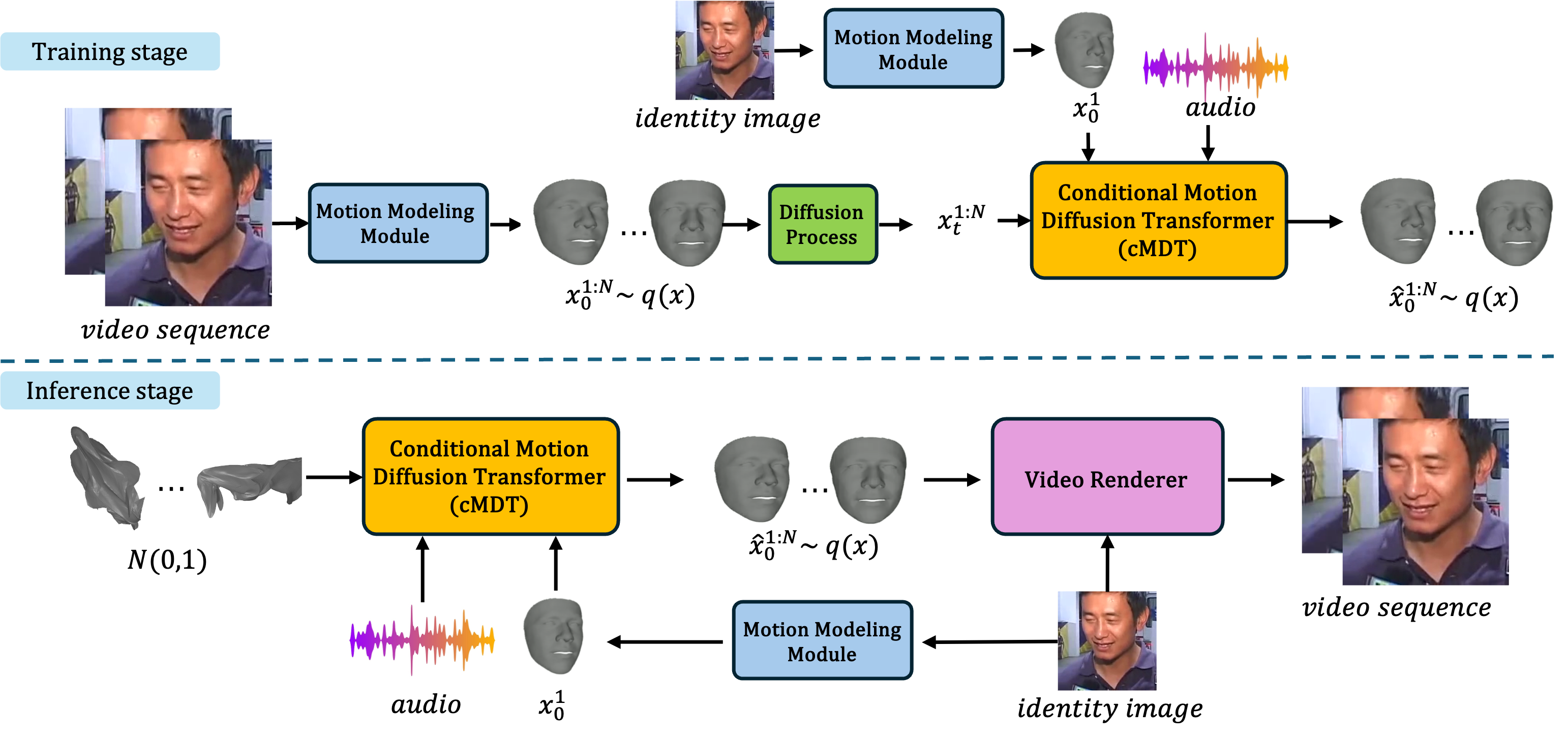
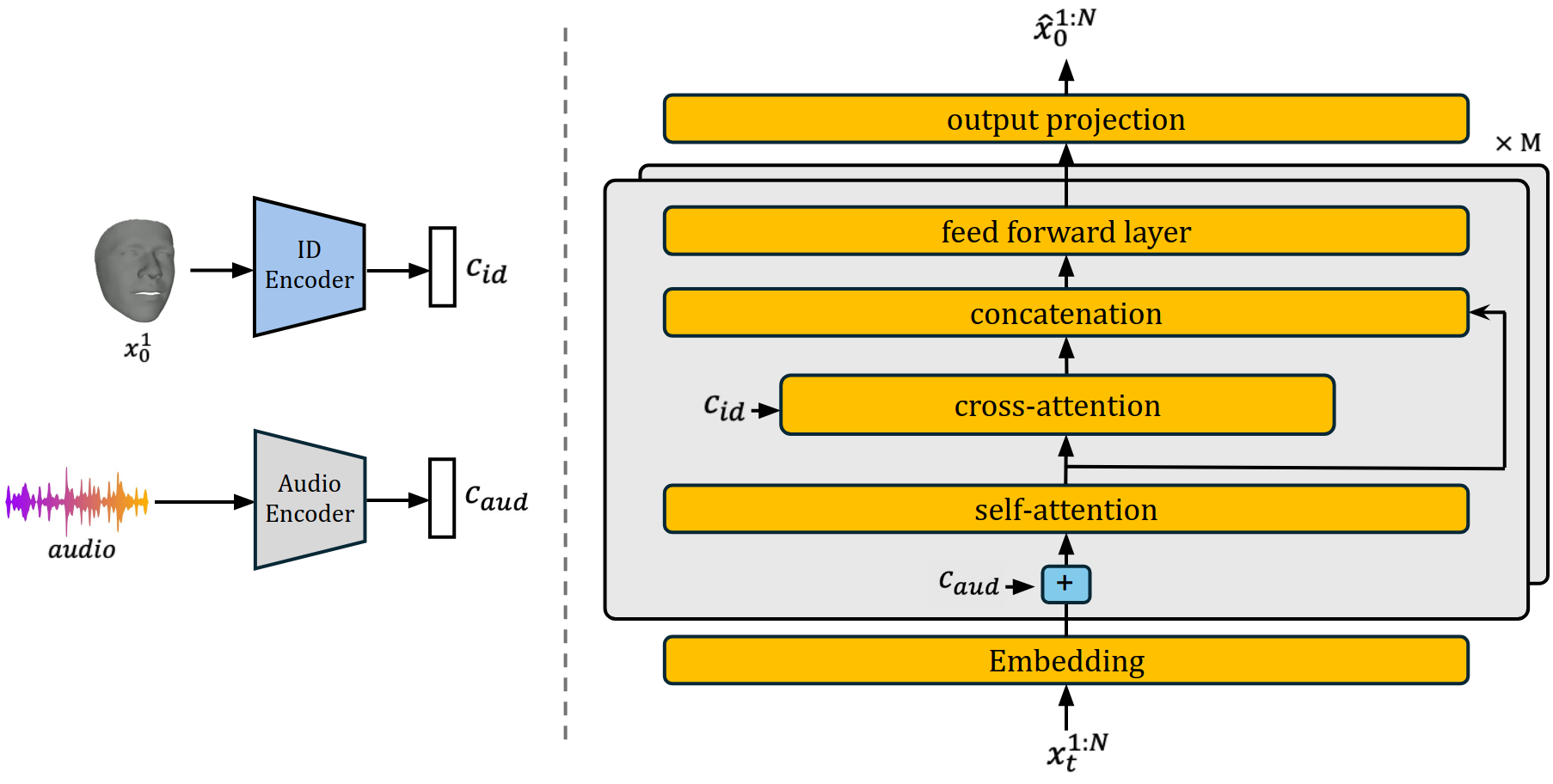
We propose Dimitra++, a novel framework for audio-driven talking head generation, streamlined to learn lip motion, facial expression, as well as head pose motion. Specifically, we train a conditional Motion Diffusion Transformer (cMDT) to model facial motion sequences employing a 3D representation. The cMDT is conditioned on two input signals: a reference facial image, which captures appearance, and an audio sequence, which drives the motion. Quantitative and qualitative experiments, as well as a user study on two widely employed datasets, i.e., VoxCeleb2 and CelebV-HQ, showcase that Dimitra++ is able to outperform existing approaches in generating realistic talking heads imparting lip motion, facial expression, and head pose.
Example videos generated on CelebV-HQ
Example videos generated on CelebV-HQ
Example videos generated on CelebV-HQ
Example videos generated on VoxCeleb2
Example videos generated on VoxCeleb2
Example videos generated on VoxCeleb2
Example videos on the CelebV-HQ dataset.
Example videos on the CelebV-HQ dataset.
Example videos on the VoxCeleb2 dataset.
Example videos on the VoxCeleb2 dataset. Despite being trained only on english language data, Dimitra++ can generate realistic videos for other languages.
Comparison with EMOPortrait.
Comparison with EMO.
Comparison with VASA-1.